
![]() AWS SQS is a message queuing service that allows you to send and receive huge numbers of messages from a queue using a simple API. Using Amazon SQS, without setting up any infrastructure, you can have a distributed and fault tolerant queuing system.
AWS SQS is a message queuing service that allows you to send and receive huge numbers of messages from a queue using a simple API. Using Amazon SQS, without setting up any infrastructure, you can have a distributed and fault tolerant queuing system.
Since SQS is a managed service, you have less visibility with traditional monitoring tools. As such, it becomes even more important to take advantage of the available monitoring tools in AWS. In this post, we’ll explain how to use CloudWatch and what is important to watch to have proper AWS SQS monitoring.
In this blog:

How to use SQS Metrics in CloudWatch
There are many SQS metrics published to CloudWatch, and looking for abnormalities and limits in these metrics is a great way to spot issues with your SQS queues. However, some metrics are more valuable than others. In this section, we’ll discuss the metrics to monitor.
NumberOfMessagesSent
One of the simplest SQS metrics to watch in CloudWatch is NumberOfMessagesSent. This metric measures the number of messages enqueued in a 5-minute interval. It can be useful for determining the health of the systems sending data to SQS. Watch this metric to make sure your producer doesn’t suddenly start sending more messages, or stop sending messages completely.
To monitor NumberOfMessagesSent, you should look at its graph in CloudWatch (for either the Average or Sum aggregation) to determine a healthy baseline. This can be done by finding the normal highs and lows for a week and then creating CloudWatch alarms for 10% above or below that window.
Why Not Use NumberOfMessagesDeleted or NumberOfMessagesReceived?
At first glance, it would seem that you want to monitor NumberOfMessagesReceived vs. NumberOfMessagesSent in SQS to make sure that all messages are being read from the queue, and NumberOfMessagesDeleted to ensure that they are being successfully processed. However, doing so would create CloudWatch alarms that are identical to the ones for NumberOfMessagesSent. To illustrate why this is a problem, consider the case when your producer unexpectedly stops. You immediately get an alert for NumberOfMessagesSent. Shortly after, when your consumers have cleared out your queue, you will get an alerts for NumberOfMessagesReceived and NumberOfMessagesDeleted. You already knew about the root problem, but were still notified two more times. Instead, we recommend using ApproximateAgeOfOldestMessage.
Additionally, we’ve found that when deleting a message from a queue, CloudWatch records the NumberOfMessagesDeleted at the creation time of the message, rather than the time you deleted the message, which is not useful for real-time monitoring.
ApproximateAgeOfOldestMessage
ApproximateAgeOfOldestMessage measures the number of seconds since the creation of the oldest message in the queue. This SQS metric is effective because if it creeps up, it means that messages are not being processed quickly enough. If you don’t have a redrive policy set for your queue, it also alerts you to messages that your consumers can’t handle and that are stuck in your queue.
To monitor ApproximateAgeOfOldestMessage, view the CloudWatch graph for the metric (using the Maximum aggregation) to determine a healthy baseline for your queue. If you typically read messages as soon as they come in, the threshold should be close to zero. If you have a more bursty workload, find the average time it takes to clear out the queue and then set your threshold 10% above that. Then create a CloudWatch alarm for when it goes over the threshold you determine.
Additionally, you’ll want to set an alarm when ApproximateAgeOfOldestMessage gets close to the retention period you set when configuring the queue. If a message gets too old, it will be discarded from the queue and you will lose that data.

Your messages will be discarded if they exceed the retention period.
Avoiding the Inflight Messages Limit in SQS
Inflight messages are the messages that have been received by a consumer, but have not been deleted or failed. In other words, they are actively being processed. For a standard SQS queue, there is a limit of 120,000 inflight messages, and and 20,000 is the limit for FIFO queues. It’s important to keep an eye on this limit because if you exceed it, you will be unable to process more messages until you reduce the number of inflight messages.
To monitor for this situation, watch the ApproximateNumberOfMessagesNotVisible metric by creating a CloudWatch alarm that alerts when the Maximum aggregation exceeds 110,000 messages for a standard queue or 18,000 for FIFO queues.
Staying Under the SQS Maximum Message Size
When you create your queue, you configure a maximum message size that ranges from 1 to 256 KB. If you exceed that, your message will be rejected. As such, it’s a good idea to watch SentMessageSize to check for messages that approach the maximum message size.

If you exceed the max message size, your message will be rejected.
When monitoring SentMessageSize, there are two strategies. If your application cannot tolerate any rejected messages, you’ll want to set a CloudWatch alarm for when the Maximum aggregation approaches your configured maximum message size. This won’t actually catch the messages that go over the max message size (since those would be rejected and would not be recorded), but will catch messages that are spiking close to the limit, giving you an indication that there may be something wrong. If you just need to keep messages from failing generally, do the same with the Average aggregation.
Ensure You’re Handling SQS Dead Letters
When a message repeatedly fails to be processed, it can be sent to a configured dead letter queue. Unfortunately, in many cases DLQs are forgotten about and messages sent there disappear into the void. To avoid this problem, you’ll need to watch the ApproximateNumberOfMessagesVisible metric for the DLQ. Just set a CloudWatch alarm for when the Sum aggregation exceeds 0 on the queue.
Why Not Use NumberOfMessagesSent?
You might be wondering why we can’t just use the NumberOfMessagesSent metric that we used before to detect messages in the DLQ. Unfortunately, in a somewhat counterintuitive way, messages being sent to the DLQ as a result of failing in the original queue do not increment NumberOfMessagesSent.
How to view SQS metrics in CloudWatch
SQS CloudWatch metrics can be viewed normally through the Metrics portion of CloudWatch, but it is also possible to use the Monitoring tab in the SQS console. This tab shows several metric graphs for each queue.

The Metric Delay Problem
SQS CloudWatch metrics are only available at a 5 minute granularity. What’s worse, these metrics often have 10–15 minutes of latency, which means that you will not be able to detect an issue in SQS when it actually happens. Because this is the case, if you need to know about issues immediately, you should monitor the producers and consumers of SQS messages in addition to SQS.
How to create SQS CloudWatch alarms
Now that we’ve determined which metrics to monitor, let’s talk about how to create CloudWatch alarms on those metrics. CloudWatch alarms are created from the CloudWatch console.
-
Click on Create Alarm.
-
Click on Select Metric and type the name of the metric into the search box.
-
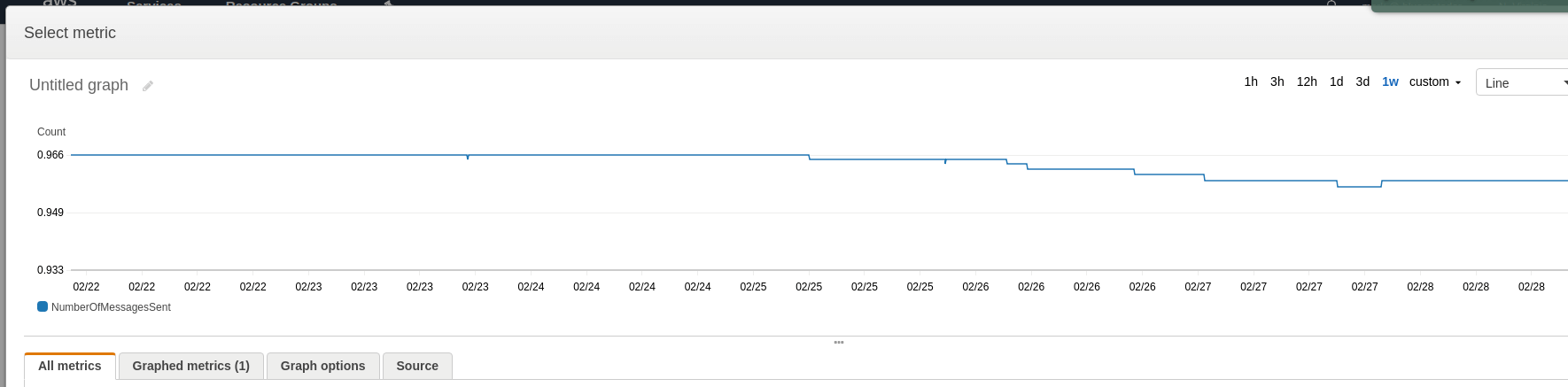
Choose the metric for the queue you’re going to monitor and look at a 1 week graph to determine what your baselines are. Click Select Metric.
-
Name and describe your alarm.
-
Configure your thresholds. You can use the thresholds described earlier in this article for each metric.
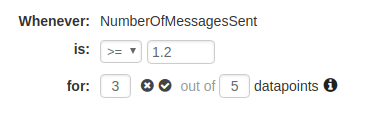
-
Choose what to do when data is missing (we recommend ignoring missing data and just keeping the previous state to keep alerts from flapping).
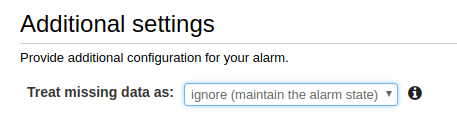
-
Set up notifications for the alarm.
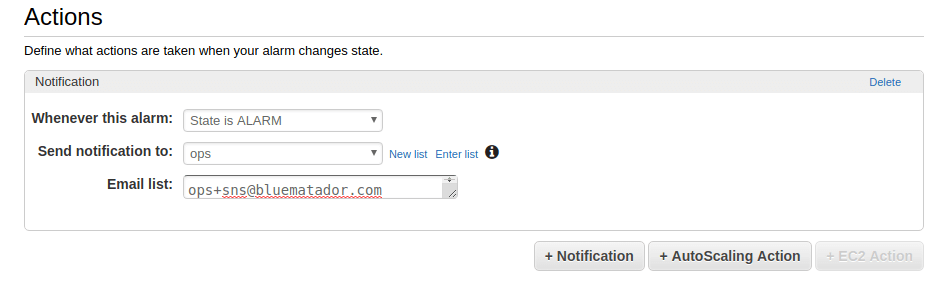
-
Click Create Alarm.
Unfortunately, since your queues likely have different baselines, you’ll have to repeat the whole process for each queue and metric combination. This might take a while...
Alternatives to CloudWatch for AWS SQS monitoring
Now you know how to monitor Amazon SQS using CloudWatch. However, it can be error prone and tedious to set up CloudWatch monitoring for all your queues (and remembering to do it for queues you create in the future is tough!). Take the manual work out of monitoring your SQS queues and use Blue Matador’s automatic setup to effortlessly watch for anomalies and errors within Amazon SQS without any configuration. It also watches your queues for configuration errors like improperly configured delays and retention parameters. Get started on automatic alerting with a free trial of Blue Matador AWS monitoring now!


