
Redshift is a fast, managed, data warehouse solution that's part of AWS. Although it is traditional SQL and meant for BI (Business Intelligence), it is designed for scalability and can support many workloads typically reserved for Big Data tools. It is protocol-compatible with PostgreSQL and is available through JDBC/ODBC, opening it up to a huge range of existing SQL tools.
Redshift uses columnar storage, which means it physically stores the data for each column in contiguous blocks, as opposed to regular transactional databases that store data in rows. This allows it to perform common analysis queries very fast. All of this is transparent to the user, but it does mean that Redshift has particular performance characteristics that should be considered when loading data and querying.
Here are some Redshift tips learned from experience to help you along.
Loading Data
Redshift is optimized for aggregations on large data sets. It is not designed for small incremental changes. It is much faster to load data into Redshift in batches.
Use several small, similarly sized batches
The ideal situation is that your data (from logs, or other sources) is already in S3. This allows you to use the COPY command that can read from S3 and load your data from multiple files in parallel.
If your source data is coming from a transactional system, it is tempting to insert data as it comes using INSERT statements. But this really going against the grain and you'll run into performance issues. You are better off going through the work of appending to S3 buckets and loading from there. I recommend using Kinesis Firehose, which allows you to push your data one at a time using an API, and it will manage the creation of S3 buckets and load the data for you using COPY commands. A good example from AWS for this here.
Scheduling

Unlike databases like SQL Server and Oracle, Redshift provides no built-in facilities for scheduling query jobs. It is an unfortunate omission as a lot of aggregation work can be done directly on Redshift using queries.
So, here are some options:
- AWS Lambda / CloudWatch Events - You can write your query jobs as Lambda scripts that get triggered using CloudWatch Events using a cron-like configuration. This is a great option if you already use AWS Lambda. But keep in mind that a Lambda can only run for up to 15 minutes, so any function that takes longer than that will timeout.
- EC2 Instance - You can deploy a small EC2 instance with some custom code of your choice that will execute the scheduled queries on Redshift. In this case you can actually use crontab, or your scheduling tool of choice. It's an extra piece of infrastructure, but it won't be doing too much work as all the work should be in the queries.
- AWS Data Pipeline - This one will require more effort and investment at the beginning, but it might be worth it for bigger ETL workloads. You'll have to put up with its archaic UI though.
Define SORT and PARTITION keys
Redshift doesn't support traditional keys or indexes. It depends on the physical layout and distribution of the data to perform well. So you should select the SORT and PARTITION keys for each table very carefully.
The SORT key will determine the order in which the data is stored for each table. Follow these best practices from AWS to choose the SORT key.
The PARTITION key will determine how data is distributed to each compute node. You can read more about it here.
Avoid Views
The Redshift query planner does not optimize a view query based on the data used in the where clause of the select. That means your query will scan the entire resultset from the view even if your query is only interested in a subset. Views are also not materialized and all data will be re-evaluated when you run a query on them.
It is better to create tables that are refreshed regularly (effectively like materialized views).
ETL
Redshift can perform a lot of the heavy-lifting when it comes to data cleanup and processing. Here are some recommendations:
Redshift as a data pipeline
It is a common practice to clean up the data before loading it into a warehouse. But with Redshift, I have found that it’s easier to load the raw data directly into a table as a first step. All cleanup operations can be performed within Redshift from that point on using queries.
Use transactions
Most DDL commands in Redshift work within a transaction and, in fact, might perform better when multiple operations are grouped together in a transaction.
This reminds me a bit of making transformations on immutable data structures on functional programming languages.
Here are a few example patterns you can use as a starting point.
Delete a large number of rows based on some predicate
Avoid DELETE statements when deleting large segments of your data. It is usually faster to recreate the table with the unwanted data filtered out:
BEGIN;
ALTER TABLE events RENAME TO events_copy;
CREATE TABLE events AS (
SELECT * events_copy WHERE event_type NOT IN (7,8)
);
DROP TABLE events_copy;
COMMIT;
Append a large number of rows to an existing table
-- assuming events_stage contains all the new events
BEGIN;
ALTER TABLE events RENAME TO events_copy;
CREATE TABLE events AS (
SELECT * FROM events_copy UNION
SELECT * FROM events_stage
);
DROP TABLE events_copy;
TRUNCATE TABLE events_stage;
COMMIT;
Perform Regular Maintenance
For performance, Redshift depends on the physical organization and sorting of the underlying data and on statistics metadata. As data is deleted/modified the physical organization of the data can change in ways that can lower performance. And the statistics can go out-of-date preventing the query planner from producing the most optimal execution plan. It is recommended that you regularly perform these commands:
- VACUUM - Reclaims space from deleted data and restores the sort order
- ANALYZE - Updates metadata statistics
Keep in mind that if you load your data in sort key order into a brand new table, you won't need to VACUUM. And the COPY command automatically updates the metadata statistics.
Visualize
Being standard SQL, Redshift will work with pretty much any visualization tool out there. Here's a couple of recommendations if you want to start out simple and cheap:
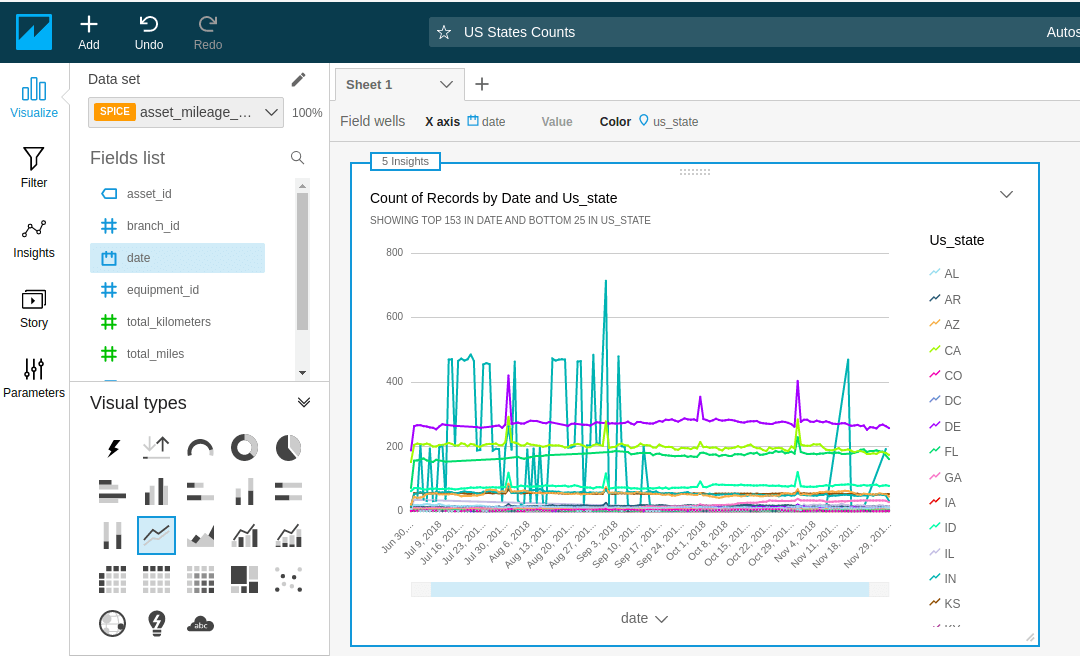
Quicksight
Part of AWS and pretty inexpensive for internal use. It is very easy to use, and it has some very cool features. With some work, you can also embed visualizations from it into your own website. You'll just have to figure out its somewhat contrive session-based pricing.
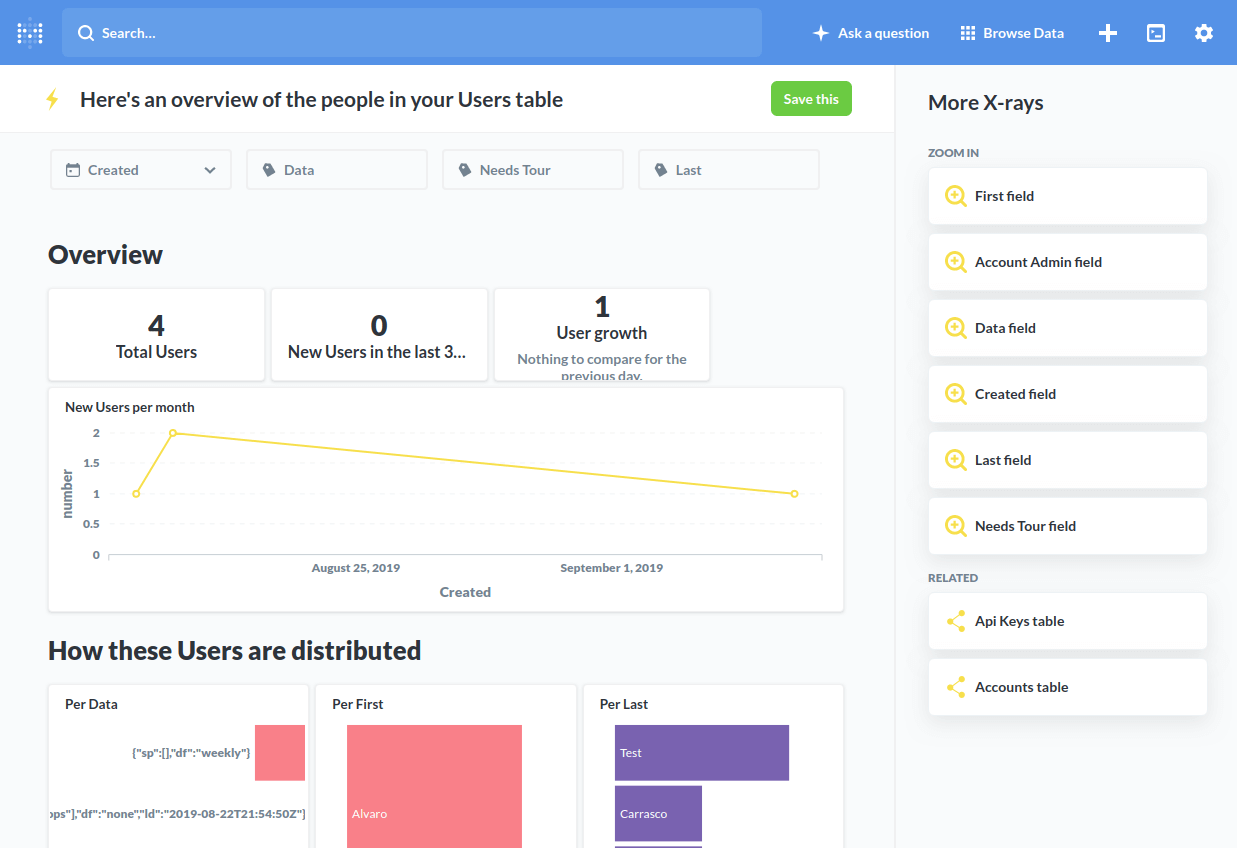
Metabase
Free and open source solution for basic data exploration. A bit more work to setup since it is not part of AWS.
Conclusion
Redshift is a powerful tool for data transformation and analysis. It is relatively inexpensive, very easy to use and can serve as an excellent starting point for BI. It is designed to be fast and scalable, but you have to consider its architecture and take some specific steps in order to get the best performance out of it.
For more information, checkout the getting started guide from AWS.


