
Troubleshooting VPC Endpoints with CameronB
There are a few, simple things in life I really, truly enjoy: a full breath of air, watching my kids learn and grow, and playing the piano immediately come to mind. I was reminded of another one after spending an hour with CameronB from DevOpsChat — full understanding of a complex problem. For me, it’s not finding a fix that works, I have to continue until I understand the underlying issues, but then it’s bliss. It’s part compulsive, and part enjoyment to internalize the “why” behind life’s and technology’s problems.
CameronB’s problem was a good one, and I’ll share all the juicy details so maybe you can have some nirvana, too. But first, a little about CameronB.
Tabs vs Spaces: Spaces
Favorite IDE: Visual Studio Code
Current OS: “Windows 10, unfortunately”
iPhone vs Android: “I have an iPhone. I think overall, Androids are better”
Favorite Superhero: “Spiderman, I guess”
Twitter Handle: @cgalt23
Context
* Disclaimer: I’m explaining the context as explained to me. One of the underlying problems in this case was a misconfiguration related to a subnet that I’ll detail at length later.
The infrastructure is incredibly simple because it doesn’t host any production traffic. CameronB was setting up an environment to play around in, and wanted to get the basics before launching any sensitive or critical workloads. The entire infrastructure is hosted on AWS and consists of two VPCs and an S3 bucket. One of those VPCs is a vestige from a previous test; while you’ll see it in the screenshots, you can completely ignore it (even including the disclaimer above), and I won’t make any more references to it.
The VPC has 8 subnets, split into public/private in 4 different availability zones. Each AZ shares the same routes, network ACLs, and base configuration except for the IP ranges (which were all reasonable). The EC2 instances in the private subnet are meant to be completely isolated from the internet, both incoming and outgoing, which is why an S3 endpoint was needed. The S3 endpoint was configured to work only with the 4 private subnets, since the public subnets don’t need a special route.
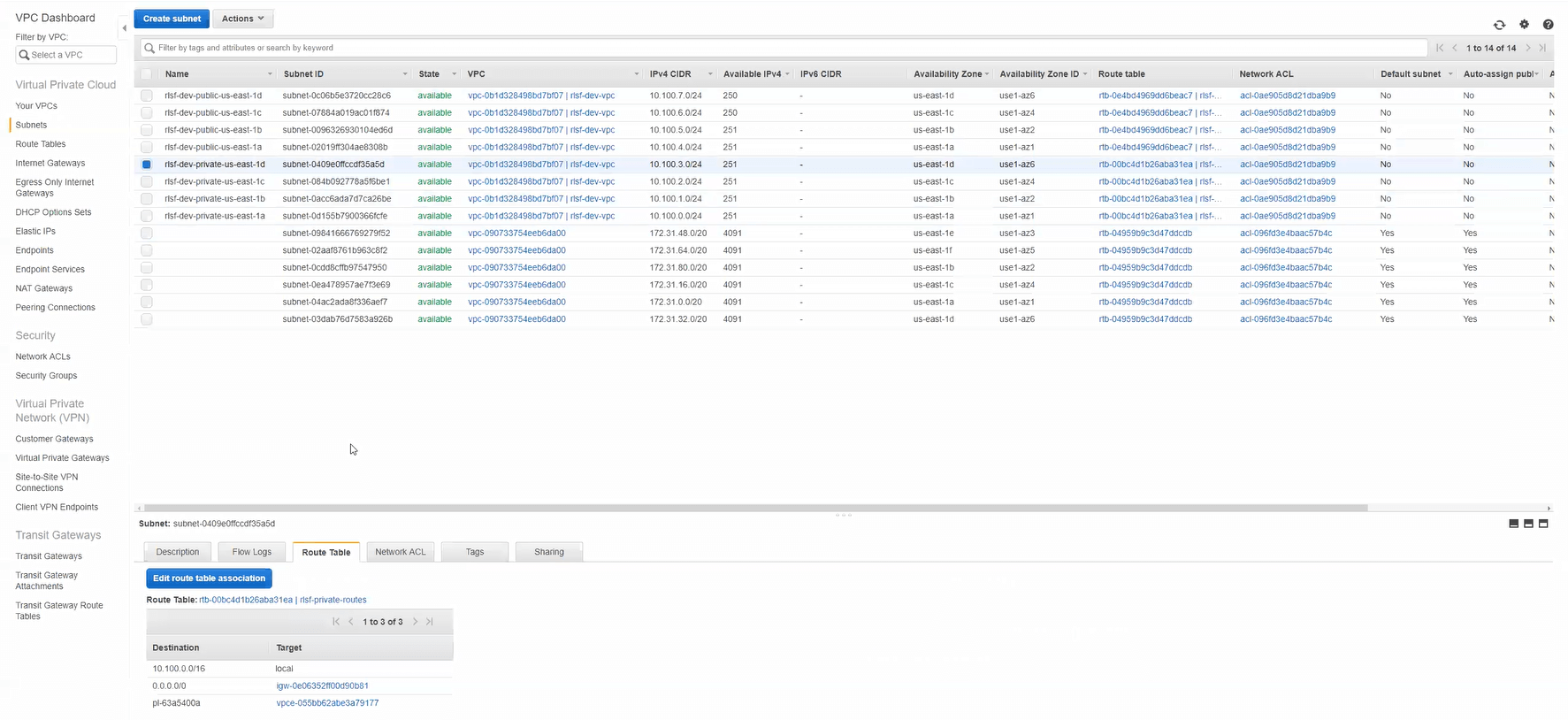
The first 8 subnets are the ones that matter, each name prepended with “rslf-dev-”. There are 4 private and 4 public subnets total, split across 4 availability zones.

The S3 endpoint is only configured to be used with the 4 private subnets.
The VPC has only 2 EC2 instances — an OpenVPN server and a test server. The OpenVPN server was in one of the public subnets, and the test server was in one of the private subnets (* read disclaimer *). The OpenVPN server was actively used to SSH into the test server. The test server was the testing grounds for the S3 endpoint connectivity. All security groups for the test server were opened to all traffic, both incoming and outgoing.
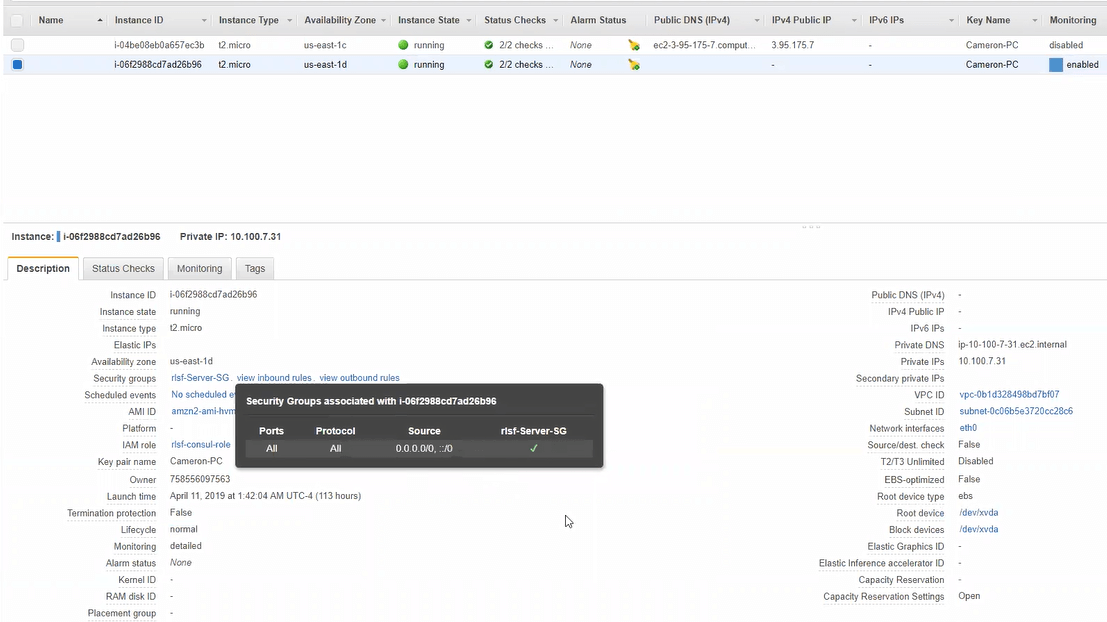
Security groups were completely open on the test server
The VPC also has an internet gateway that’s used in the configuration of all the route tables. After local (VPC) traffic and the S3 gateway traffic, the internet gateway is used for 0.0.0.0/0. There are no NAT gateways in this VPC.
All of this infrastructure explained above is completely managed by Terraform scripts, except for the S3 endpoint itself (* read misconfiguration disclaimer at the top *). Terraform manages the CIDR space, EC2 instances, security groups, S3 bucket, and everything else.
Symptoms
While Cameron could SSH to the test server through the OpenVPN server, he couldn’t use the AWS CLI to access his S3 bucket. The call consistently hangs for as long he’s willing to wait. He tried multiple S3 commands, multiple buckets, multiple objects, and multiple configuration options — they all failed via timeout. You can see that Cameron also tried to specify “--region” which he heard might help resolve to the correct region. It was easy to try, but it didn’t work.
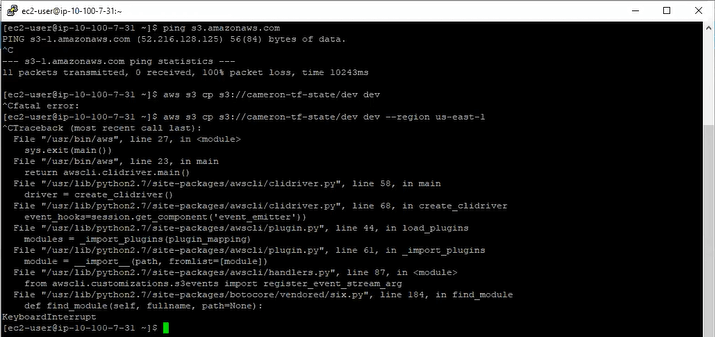
AWS CLI hangs, regardless of options, command, or bucket
Even pings to S3 failed. Feel free to try on your own computer, but pinging S3 from my computer right now works just fine. The pings also fail via timeout. Interestingly, though, the DNS query for s3.amazon.com did not fail; the domain properly resolves to the appropriate address.
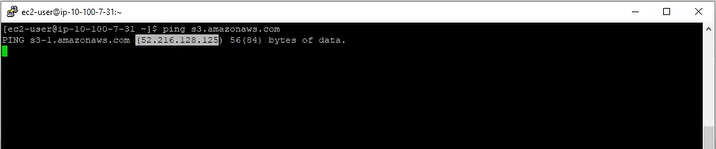
Pings to S3 also timeout, but DNS works fine.
After some initial testing, we uncovered that AWS was not the only unreachable service on the internet. Pinging Google and every other website yielded the same result. This shouldn’t be totally surprising, though, because the instance is intended to be private. The whole purpose of the S3 endpoint was to avoid setting up connectivity with the public internet.
Theories
Here’s what we tried, in order. The order matters, because we found multiple issues down the rabbit hole. Each issue was obfuscating the rest, which made it a mess to unravel, but we did finally get through it and get Cameron the setup he was hoping for.
Theory #1: Security groups or network ACLs are set up incorrectly. I’ve already shown up above that security groups were correct, the next screenshot is what every ACL looked like (all correct). Nonetheless, it was my first thought, and a decent place to start anytime you have connection issues in AWS.
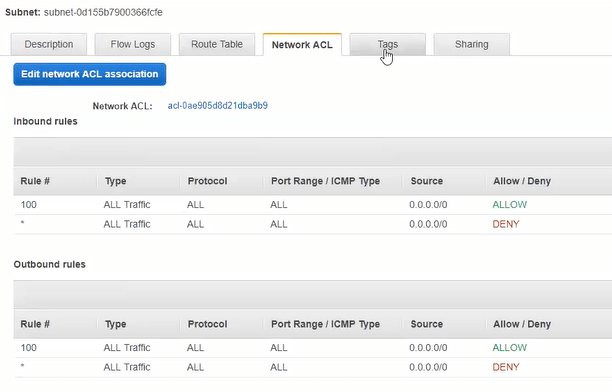
Network ACLs for all subnets within the applicable VPC
Theory #2: S3 endpoints are currently not working. It hasn’t happened for a long time, but when S3 endpoints were first rolled out, they would go down for hours at a time. Configuration would be untouched, everything would be fine, and then BOOM! No S3 connectivity. When these would happen (back in 2013ish), my entire production would grind to a halt on timeouts. The fix was to disable the endpoint and see if that fixed the problem. Cameron disabled it to test, but it had no bearing on the issue, because the test server didn’t have connectivity to S3 otherwise.
To thoroughly vet this idea of the S3 endpoint not working, we had to add a NAT gateway to the private subnets and setup routing for 0.0.0.0/0 to go through the NAT gateway. Surprisingly, that didn’t work. In fact, it still couldn’t get to anything out on the public internet!
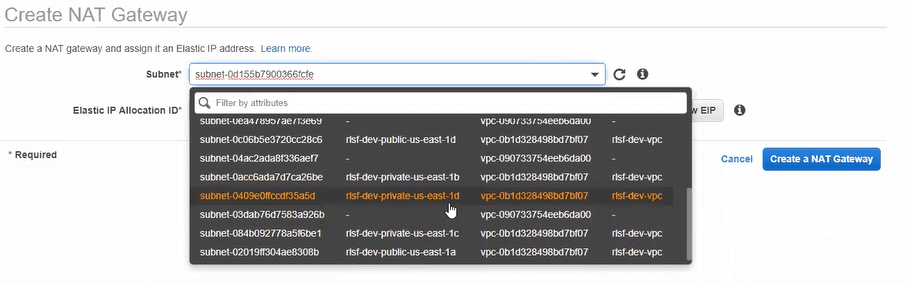
Creating a NAT gateway in one of the private subnets
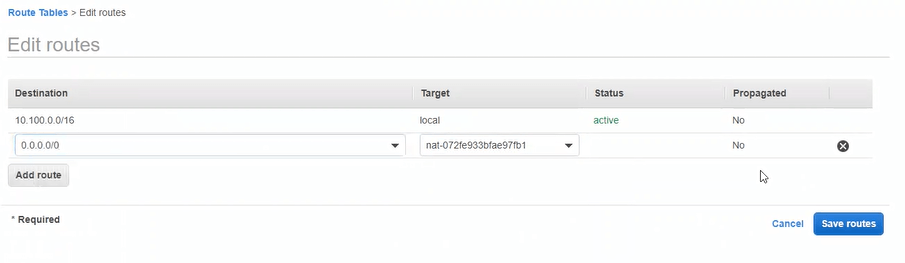
Adding the NAT gateway route for 0.0.0.0/0
At this point, we confirmed that the internet connectivity was not scoped to AWS, not impacted by the presence or absence of the S3 gateway, and that the instance was accessible via private subnets (because we were SSH’d to it) but couldn’t get access to the public internet.
Theory #3: There must be a problem with the route tables on the instance. We looked at OpenVPN. We looked at traceroute. We looked at the default routes on the test server. We compared them against other instances, our own computers, and previous knowledge. Nothing looked out of the ordinary. As much as I would have loved for it to be a problem with OpenVPN (initial configuration can be tricky), it wasn’t involved at all. The test server could communicate with every private IP address on the network, in every availability zone, in public and private zones, including the subnet controllers at 10.*.0.1.
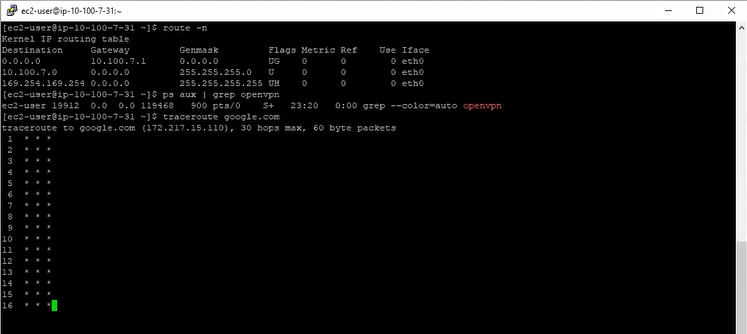
Route tables and traceroute match expectations. Asterisk in traceroute means “timed out”.
Theory #4: We missed something simple. This wasn’t a theory so much as it was a lucky glance. While Cameron was clicking through the AWS console with lightning speed, I happened to catch that the test server was in a public subnet, not a private subnet! I can’t believe I didn’t catch this in the first 5 minutes that Cameron was showing me around.
First, let me note that this was the configuration error, and the cause for the disclaimers above. This instance was not managed in Terraform. The incorrect launching was a manual error. If you have a networking error, start with the subnets!
To remedy this, we launched a new instance in a private subnet, hoping that all of our problems were solved… Nope.

Launching an instance in a private subnet
So, at this point, the test server is correctly in a private zone. The S3 endpoint is currently disabled. The NAT gateway is still enabled on the private zone. The route table still includes the NAT gateway for 0.0.0.0/0. DNS still works, and ping to the public internet still doesn’t.
Theory #5: We must have set up the NAT gateway wrong or it malfunctioned. At this point, we’re positive that we should have internet connectivity with respect to subnets, ACLs, security groups, and instance configuration. We agreed to delete the current NAT gateway and create another one.
At this point, it’s important that I emphasize how fast Cameron is at using the AWS console. It’s incredibly hard to follow. He’s like The Flash, if The Flash had just drunk 50 Redbulls. Insanely quick, but impossible to see what was happening on the screenshare.
While re-creating the NAT gateway, my screen paused on his selection of the private subnet. That’s the problem with the NAT! Anything that requires public internet cannot be put in the private subnets! This applies to NAT gateways, public ELBs, public ALBs, and probably more. This time, we selected a public subnet, updated the route table, and tested ping. It worked!
Remember picking the private subnet for the NAT gateway? Don’t do that.
We could reach the public internet. Traceroutes were running correctly. The AWS CLI calls succeeded. Everything was perfect! We re-enabled the S3 endpoint, disabled the NAT gateway, and it continued to work.
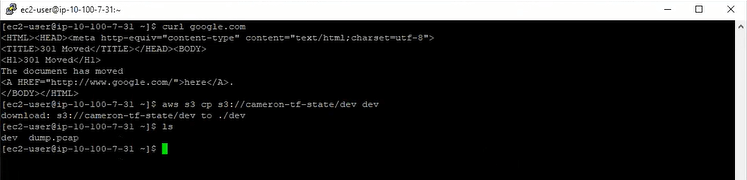
Public internet accessible, AWS CLI working

Instance in private subnet, NAT gateway in public subnet. Nailed it.
Solutions
Cameron’s problem had 3-4 separate solutions.
Solution #1: Make sure instances are in the right subnet. We never would have seen the other problems if the test instance was in the right subnet.
Solution #2: Public subnets must have internet gateways, private subnets may have NAT gateways. The routing rule for 0.0.0.0/0 must go through the internet gateway or NAT gateway for that subnet. Also, every instance in a public subnet needs a public IP address.
At one point during all the theory testing, this was the problem. It happened during Theory #2 after we disabled the S3 endpoint. Since Cameron thought he launched the test server in a private subnet, he never added a public IP address to it. All SSH traffic went to the private IP. We never specifically realized this until the end during the post-mortem.
Solution #3: Interfaces for your NAT gateways and public ELBs must be in a public subnet. These services will follow the routing rules of the subnet to which they belong.
To connect this with Solution #2: If you have a private subnet that needs access to the public internet, you need a public subnet routing 0.0.0.0/0 through an internet gateway. You also need a NAT gateway whose network interface is in that public subnet. Then you need the private subnet to route 0.0.0.0/0 traffic through the NAT gateway. None of the instances in the private subnet should have a public IP.
Solution #4: The S3 endpoint could have been enabled for the public subnet. Most of the time, there’s no good reason to limit traffic through an S3 endpoint. It saves money on your gateway bandwidth. If the S3 endpoint had been enabled for the public subnets, Cameron never would have had this problem (although he also would have never realized all the other problems with his network).
Learnings
Always check for simple answers first. And then double-check. Each one of the solutions we found could have been identified in a matter of minutes if we knew what to look for. It’s worth double-checking everything.
In AWS VPC, DNS is handled through the subnet controller. In all the testing, we couldn’t get to the public internet, but we could get DNS results. This is because all DNS queries are local, and go to the subnet controller that AWS sets up for you. Every subnet has one, and it’s always the first IP address in the CIDR. If your subnet is 10.0.0.0/8, then the subnet controller is at 10.0.0.1.
Don’t wait 7 days before asking for help. Cameron pulled his hair out (I assume figuratively) for 7 days trying to get this endpoint to work. We solved it together in just over an hour. And, we learned some valuable things along the way. Whether it’s me that’s helping (Tweet to me at @GuardianDevOps), someone you work with, or a rubber duck, ask for help after about an hour.
Credits
![]()
Guardian DevOps is a free service that puts you in contact with DevOps and SRE experts to solve your infrastructure, automation, and monitoring problems. Tag us in a post on Twitter @GuardianDevOps, and together we’ll solve your problems in real time. Sponsored by Blue Matador.
Tweet to @GuardianDevOps Follow @guardiandevops
![]()
Blue Matador is an automated monitoring and alerting platform. Out-of-the-box, Blue Matador identifies your AWS and computing resources, understands your baselines, manages your thresholds and sends you only actionable alerts. No more anxiety wondering, “Do I have an alert for that?” Blue Matador has you covered.


